今天要往更下游走,Exposures 可以理解為 dbt 的 output,也就是說經過 dbt 轉換的資料都被用在哪些地方,例如我們在 Teamson 是以 Tableau 為主。
另外,本系列文章在 BigQuery 主要只有用到兩個 dataset,正式環境用 dbt_prod、開發環境用 dbt_dev。
table 或 view 的名稱則是 dbt model 的名稱。
然而某些情況,我們希望可以拆成不同 dataset,或是希望 table/view 可以使用不同於 dbt model 的名稱,這就是後半段要討論的,custom outputs。
在 models 資料夾底下新增 yaml 檔,檔名可以取 exposures.yml 或任何檔名皆可。
在 yaml 檔中定義 exposures,範例如下:
version: 2
exposures:
- name: tableau_data_source
type: analysis
label: Tableau Data Source
description: Analytics ready datasets for Tableau
tags: ['business_intelligence']
depends_on:
- ref('customers')
owner:
name: Stacy Lo
定義完成後,就會在 lineage graph 呈現。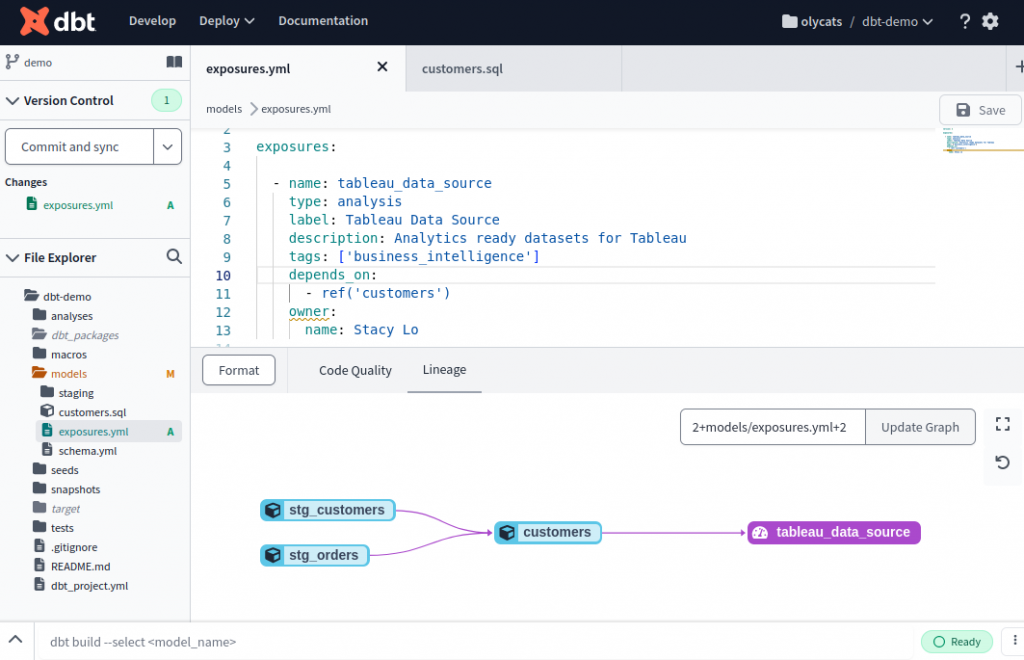
定義完 exposure 之後,重新產出文件,就可以在文件頁面看到 exposures 的區塊。
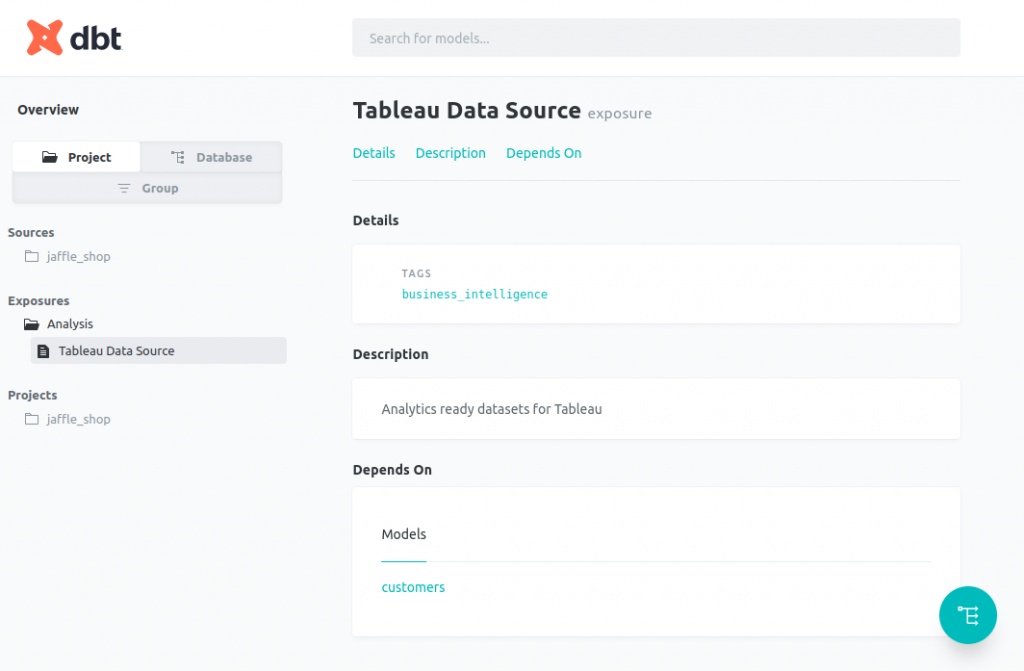
Exposures 底下的資料夾是依 exposure types 分類:
資料夾底下會列出各個 exposures,顯示的是 label,較易閱讀的名稱,而非 exposure 在 dbt 內部的物件名稱。
右邊區塊文件的內容即為剛剛定義的 description, tags, 以及 depends on。
以下列出一些我想到的 exposure 使用情境:
dbt build --select +exposure:tableau_data_source
在 model 裡面的 config 即可定義 custom schema 和 alias。例如
{{
config(
schema='customers',
alias = 'primary_data'
)
}}
Schema 在 BigQuery 指的就是 dataset。
如果有設定 custom schema 的話,輸出的 dataset 就會變成 {{ default_schema }}_{{ custom_schema_name}}。
以上面的例子來說,若是在開發環境
正式環境則是
Alias 就是別名,輸出到目標資料庫的 view 或 table,我們可以設定不同於 dbt model 的名稱。
以上面的例子來說,如果我們已經定義 dataset 為 customers,而我們的 model 名稱也叫做 customers,輸出到 BigQuery 就會變得有點像繞口令
這時候我們或許會想換個名稱,例如
就算已經設定了 custom schema,出來的結果可能還是不符合期望。
現在我們輸出的結果是
但是在正式環境,我們可能希望 dataset 的名稱就叫做 customers,不希望包含前綴 dbt_prod_。
dbt 在產生 custom schema name 的時候是用內建的 macro generate_schema_name
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name is none -%}
{{ default_schema }}
{%- else -%}
{{ default_schema }}_{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}
如果我們希望使用改變邏輯,我們可以在專案底下建立同名 macro。
如果專案底下有同名 macro,就會覆蓋預設的 macro。
舉例來說我會這樣做:
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name is none -%}
{{ default_schema }}
{%- else -%}
{% if default_schema == 'dbt_prod' %}
{{ custom_schema_name | trim }}
{% else%}
{{ default_schema }}_{{ custom_schema_name | trim }}
{% endif %}
{%- endif -%}
{%- endmacro %}
這裡要注意一個地方,雖然我們希望輸出到 dataset: customers,但是只限正式環境。開發環境千萬不能也輸出到 dataset: customers,否則開發階段的操作就會影響到正式環境。
以上的例子是去判斷 target.schema,如果為 dbt_prod 的話就不要包含 {{ default_schema }}_ 的前綴,如果不是 dbt_prod 的話就維持預設。
如何判斷正式環境有好幾種方法,除了 target.schema 之外,也可以用本系列文尚未介紹到的,target.name 或環境變數去判斷。再過幾天會介紹如何在本機用 dbt Core 和 dbt Cloud 同時開發,兩邊的環境設定也是需要納入考量的的因素。
今天討論了 exposures 和 custom outputs,雖然是兩個不相干的主題,但都和下游輸出有關。
明天的主題:專案架構及命名原則
歡迎加入 dbt community
對 dbt 或 data 有興趣 👋?歡迎加入 dbt community 到 #local-taipei 找我們,也有實體 Meetup 請到 dbt Taipei Meetup 報名參加


 iThome鐵人賽
iThome鐵人賽